Published
- 5 min read
Lesson learned on deploying Minio with CIFS backend. Part 1
This is going to be my devops rant.
I have a k8s cluster in Hetzner and managed by Rancher. The k8s distro I’m using is RKE. The default storage provisioner is Longhorn.io.
Longhorn.io has a nice feature they called volume snapshots. It produces snapshots of volumes at the block level. It also snapshots by creating a diff. Longhorn.io also offers sending snapshots as backup over to a separate s3 or NFS endpoint.
Now here’s come the good part. Over time, I have multiple volumes managed by Longhorn.io. When I want to upgrade Longhorn.io engine and manager, I want these volumes be backed up first. So I need either s3 compatible service like MinIO, or NFS. I choose s3.
Installing MinIO itself is quite straightforward. I am using Bitnami’s Helm Charts of MinIO. I deployed one instance, then naturally the storage MinIO is using comes from Longhorn.io. I tried creating backup of one of my volumes with around 5GB of data. No hiccups. It’s working fine.
Now, the catch is this.
It doesn’t make sense if I used Longhorn.io as MinIO storage backend because eventually I want to backup all Longhorn.io volumes into MinIO. It has to be using separate backend storage. Otherwise, MinIO will not work if the Longhorn upgrade fails.
I thought, things will be as simple as swapping storage driver in kubernetes, but I was proven wrong.
These will be a series of blog posts to record my failures. So far, I can’t get it to work.
Architecture
This is what I have in mind.
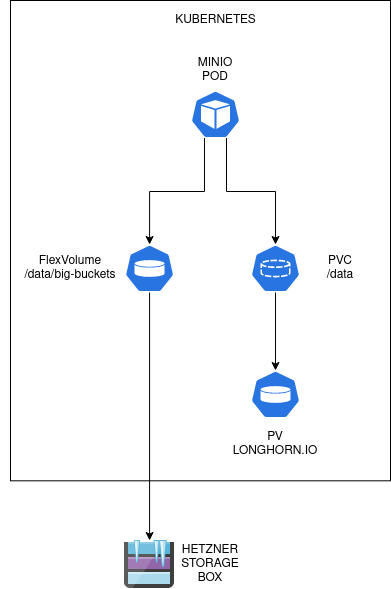
I want to put two different storage backend on /data path inside the MinIO pod. The regular buckets comes from Longhorn.io. I figured for regular buckets (not for backup), I want to use Longhorn volumes because it is inside the cluster, and it’s close. Then I want to attach special bucket for archiving purposes. This bucket uses Hetzner Storage Boxes as it’s backend. It’s cheap, but a little bit slow. This one comes from outside the cluster, from what Hetzner called Hetzner Robot service.
Implementation
We need to figure out how to mount Hetzner Storage Boxes inside our MinIO pod as volume and filesystem paths. I’ve read Hetzner documentation and I’m going to use the CIFS share.
Mounting CIFS in a node is easy. You add entry in fstab and provide the CIFS credentials. However, since we are going to mount the volume in a pod, we can’t mount the CIFS share into the node and then use host path volume mount. We have to mount the share directly to the pod.
After several search. I figured we can use Kubernetes FlexVolume resource. With FlexVolume, you can either define volume directly in the Pod/Deployment spec. Alternatively you can create a PV with flexVolume spec and then create PVC to bind it. It’s quite simple to just use the FlexVolume in Deployment spec. So I’m going to do just that.
Next, we need to find the FlexVolume driver for CIFS. Fortunately, we have one. There’s a driver called fstab/cifs. The explanation is quite simple too. You need to install the driver first.
You need to execute this on each and every k8s worker node:
VOLUME_PLUGIN_DIR="/usr/libexec/kubernetes/kubelet-plugins/volume/exec"
mkdir -p "$VOLUME_PLUGIN_DIR/fstab~cifs"
cd "$VOLUME_PLUGIN_DIR/fstab~cifs"
curl -L -O https://raw.githubusercontent.com/fstab/cifs/master/cifs
chmod 755 cifs
I have several problems with this approach.
- I have many nodes, and we may have new nodes created or old nodes deleted. It will be difficult to reapply that command to make sure every nodes will have it.
- I am using RKE, which means kubelet is running as a container inside the node. We need to modify the command so that the driver is installed in the kubelet container.
Since we are going to see if the approach is feasible before making it a cluster-wide change, we are going to use quick fixes.
For problem #1: Create a dedicated node where the MinIO pod will run. Install the driver there. Provide Node labels. Add scheduling and nodeAffinity spec for MinIO deployment.
For problem #2: After doing some tests, it seems that kubelet mount almost all the rootfs of the node. The directory /usr/libexec/kubernetes/kubelet-plugins/volume/exec is one of them. So everything is fine.
After installing the driver and restarting kubelet (in my case here docker restart kubelet). We will have the driver ready with the proof:
VOLUME_PLUGIN_DIR="/usr/libexec/kubernetes/kubelet-plugins/volume/exec"
$VOLUME_PLUGIN_DIR/fstab~cifs/cifs init
It should return a success JSON map value.
Next, we need to create the CIFS secret resource. You can create it as YAML manifests first or just execute kubectl create command.
kubectl -n <namespace> create secret generic cifs-secret --from-literal=username=<username> --from-literal=password=<password>
If you prefer to store it as manifest, don’t forget to base64 encode your secret values. Or, just use the same command above, but append --dry-run=client -o yaml arguments.
apiVersion: v1
data:
password: cGFzc3dvcmQ=
username: dXNlcg==
kind: Secret
metadata:
creationTimestamp: null
name: cifs-secret
Next, in MinIO deployment spec, I changed the volumes and volumeMounts. (Other keys are omitted for brevity).
kind: Deployment
spec:
template:
spec:
containers:
- name: minio
volumeMounts:
- name: data
mountPath: /data
- name: data-cifs
mountPath: /data/backup-bucket
subPath: backup-bucket
volumes:
- name: data
persistentVolumeClaim:
claimName: minio-data
- name: data-cifs
flexVolume:
driver: 'fstab/cifs'
fsType: 'cifs'
secretRef:
name: 'cifs-secret'
options:
networkPath: '//server/share'
mountOptions: 'dir_mode=0755,file_mode=0644,uid=1001,gid=1001'
Note that in the above spec, I put uid=1001,gid=1001 as the mount options because MinIO pod is using that security context as user with id/gid 1001/1001 and fsGroup: 1001.
Also, as you can see, I mount the CIFS share as a bucket inside /data directory where MinIO served. Effectively, this is an overlay mounts. I expect that when user push into the bucket backup-bucket it will get pushed to /data/backup-bucket which is a CIFS share mount. Any other bucket will get pushed to /data/other-bucket which is a Longhorn.io volumes.
HOWEVER This doesn’t work.
Apparently, even though the CIFS share is mounted (yay!). MinIO refuses to serve overlay mounts because it wants to control locks of the whole folder. Overlay mounts don’t allow that. MinIO doesn’t want to serve a folder that have a cross mount.
Conclusion
- This architecture doesn’t work due to limitation on overlay mounts.
- But, mounting CIFS share via FlexVolume works
We’re going to revise the architecture a bit in the next part of the articles: Part 2